Process Overview
The Patient360 structured retrieval workflow is executed when $p360-retrieve is called for a patient. The workflow retrieves clinical documents from connected networks, processes those documents, and produces a structured dataset stored in your tenant.
Workflow Diagram
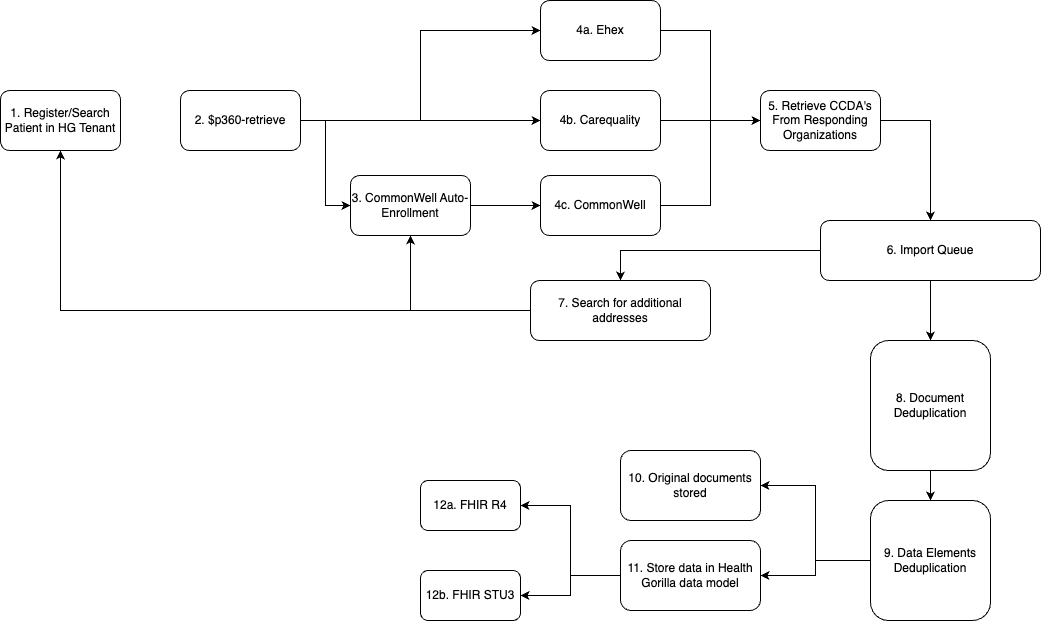
Retrieval Process
1. Register or Identify Patient
A patient is created in your tenant or an existing patient is retrieved. The result of this step is a Patient FHIR resource ID (HG ID), which is used to initiate retrieval.
2. Initiate Retrieval
The $p360-retrieve operation is called using the patient’s HG ID. This starts the asynchronous retrieval and processing workflow.
3. CommonWell Auto-Enrollment
If the patient is not already linked to a CommonWell Person record, Health Gorilla attempts to match and link the patient automatically.
Matching requires:
All of the following fields match exactly (case insensitive):
- First name
- Last name
- Date of birth
- Gender
- ZIP code
AND at least one of the following:
- Matching email
- Matching phone number
- Matching Address1 and city
If no match is found, the patient is enrolled as a new Person in CommonWell.
4. Query and Retrieve Clinical Records
Clinical records are retrieved from networks your organization is licensed to access.
- Carequality and eHealth Exchange queries are performed using a default 50-mile radius around the patient’s ZIP code
- The search radius can be extended through configuration
- CommonWell retrieval uses linked Person records
- TEFCA QHIN-connected participants are queried based on network availability and responder behavior
Results depend on participating organizations, matching success, and consent enforcement.
5. Document Ingestion
Retrieved documents are placed into a processing queue. Documents may arrive at different times depending on network response and retrieval latency.
6. Address Expansion and Requery
Additional addresses identified within retrieved documents are added to the patient record. If new address information is found, additional network queries may be performed using the updated demographics to retrieve more records.
7. Document Deduplication
Duplicate documents are identified and removed. This prevents redundant storage and ensures the same document is not imported multiple times across retrieval attempts.
8. Data Extraction and Deduplication
Clinical data is extracted from retrieved documents and normalized. Duplicate clinical data elements across documents are reconciled to produce a consistent dataset. The level of structured data available depends on the content and format of source documents.
9. Document Storage
Original documents that remain after deduplication are stored in the patient’s record in your tenant. These documents are accessible through the DocumentReference resource.
10. Structured Data Storage
Extracted clinical data is stored in the Health Gorilla data model and made available as FHIR resources. This structured dataset supports downstream access and workflows.
11. FHIR Access
Stored data, including documents and structured clinical data, is available through Health Gorilla FHIR APIs (STU3 and R4). Subsequent FHIR queries return data that has already been retrieved, processed, and stored.
Key Characteristics
- The workflow is initiated by
$p360-retrieve - Retrieval and processing are asynchronous
- Data is retrieved from multiple networks based on availability and matching
- Documents are processed into structured data where supported
- Results are stored in your tenant for reuse
- The resulting dataset is used by Patient360 features such as Patient Chart
Updated about 1 month ago